Qwen3¶
约 1142 个字 84 行代码 预计阅读时间 5 分钟
Qwen3ForCausalLM
├── self.model (Qwen3Model)
│ ├── embed_tokens
│ ├── layers[0..27]
│ └── norm
└── self.lm_head (ParallelLMHead)
Qwen3Attention¶
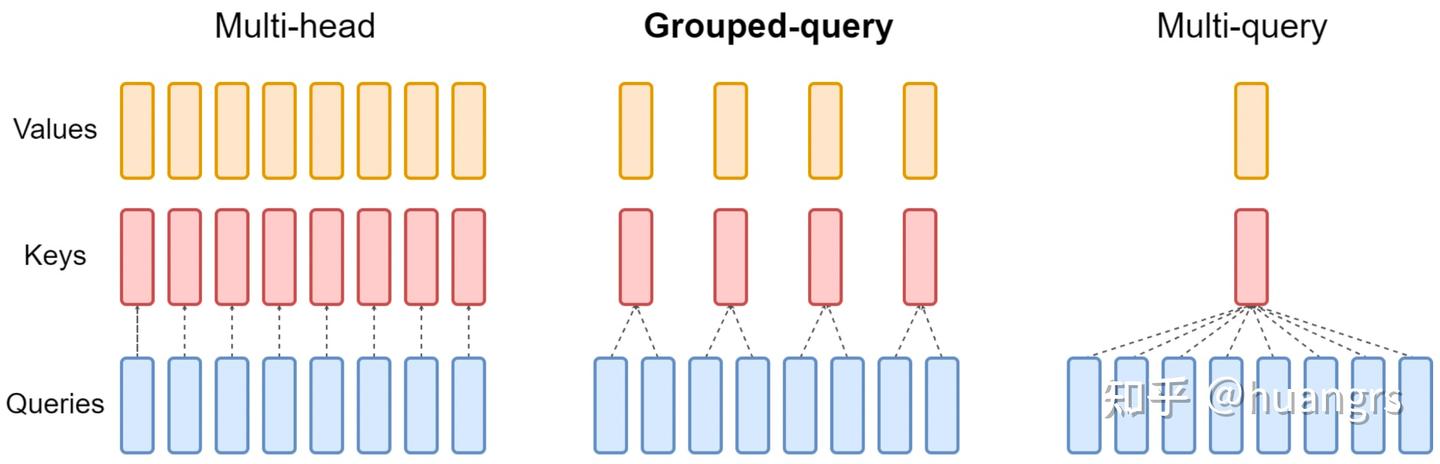
MHA、MQA、GQA 三种注意力机制¶
MHA 多头注意力:h 个 Query、Key 和 Value 矩阵,每个头都有一份不同的 Key、Query、Value 矩阵。所有注意力头的 Key 和 Value 矩阵权重不共享。
MQA 多查询注意力:与 MHA 不同的是,MQA 让所有头之间共享同一份 Key 和 Value 矩阵,每个头只单独保留一份 Query 参数,从而大大减少 Key 和 Value 矩阵的参数量。
GQA 分组查询注意力:将查询头分成 G 组,每个组共享一个 Key 和 Value 矩阵。GQA-1 只有单个组,等效于 MQA;GQA-H 组数与头数相等,等效于 MHA。
num_head表示 Q 的 head 数,num_kv_head表示 KV 的 head 数。两者关系: -num_kv_head = 1→ MQA -1 < num_kv_head < num_head→ GQA -num_kv_head = num_head→ MHA
什么是注意力头(Head)¶
一个 token 的 hidden state 是 1024 个数的一长串。做 attention 时不是 1024 个数一把梭,而是切成 16 份,每份 64 个:
[0.1, -0.3, 0.7, ... 共 1024 个]
切成 16 份:
份 0: [0.1, -0.3, ..., 0.2] 64 个数
份 1: [-0.5, 0.8, ..., 0.4] 64 个数
...
份15: [0.9, -0.1, ..., 0.3] 64 个数
每一份就叫一个 head,head_dim = 64 就是一份有几个数。16 份各自独立做 attention——每份自己算 Q/K/V,自己算相关分数,自己加权。相当于 16 个独立的大脑从 16 个角度去理解这句话:head 0 可能学习"动词-主语"关系,head 1 可能学习"形容词-名词"修饰,head 2 可能学习长距离依赖。最后 16 份结果拼回去,恢复 1024 维。
所以三者的关系是:
Attention 的 Forward 流程¶
forward 做了 7 步:先把 hidden states 拆出 QKV,转成多头的 shape,经过 QK 归一化(Qwen3 特有)和 RoPE 旋转位置编码,再执行 Flash Attention 读写 KV cache,最后过输出投影。代码对应:
def forward(self, positions: torch.Tensor, hidden_states: torch.Tensor) -> torch.Tensor:
# ① QKV 融合投影
qkv = self.qkv_proj(hidden_states)
# ② 拆成 Q、K、V 三段
q, k, v = qkv.split([self.q_size, self.kv_size, self.kv_size], dim=-1)
# ③ reshape 成多头形状 [N, heads, head_dim]
q = q.view(-1, self.num_heads, self.head_dim)
k = k.view(-1, self.num_kv_heads, self.head_dim)
v = v.view(-1, self.num_kv_heads, self.head_dim)
# ④ Qwen3 特有:Q、K 各自 RMSNorm
if not self.qkv_bias:
q = self.q_norm(q)
k = self.k_norm(k)
# ⑤ RoPE 旋转位置编码
q, k = self.rotary_emb(positions, q, k)
# ⑥ Flash Attention:读写 KV cache
o = self.attn(q, k, v)
# ⑦ 输出投影
output = self.o_proj(o.flatten(1, -1))
return output
Qwen3MLP¶
MLP(Multi-Layer Perceptron)多层感知机,self-attention 之后的前馈网络。
前馈网络 Feedforward Network(FFN): 信号单向流动,没有循环没有反馈。
attention 做的是 token 之间的关系,MLP 做的是每个 token 自身的非线性变换。
为什么需要非线性?如果全部是线性变换,W2 × W1 × x 永远等价于 W3 × x——不管叠多少层都等于一层,模型的表达能力被封死在线性空间的边界里。非线性激活打破了这种确定性,让模型可以逼近任意复杂的函数,学到的模式不再被线性关系框住。
SwiGLU 的特别之处在于两道门:gate 控制信息通过量(SiLU 压缩到 0~1),up 传递实际内容,两者逐元素相乘完成筛选。
def forward(self, x): # x: [N, hidden_size]
gate_up = self.gate_up_proj(x) # → [N, 2*intermediate]
# SiLU(gate) × up
x = self.act_fn(gate_up) # → [N, intermediate]
x = self.down_proj(x) # → [N, hidden_size]
return x
Qwen3DecoderLayer¶
为什么 norm 放在 attention/MLP 之前(Pre-norm)而不是之后(Post-norm)?
- 原始 Transformer 的 Post-norm 在深层网络里梯度容易消失,Pre-norm 让残差路径更通畅。
公式化表示两种 Norm 方法:
其中 \(F_t(\cdot)\) 表示 Multi-Head Attention 或 FFN,下标 \(t\) 表示层数。简单理解:残差连接之前做 Norm 是 Pre-Norm,之后是 Post-Norm。
还有一种写法是把 Norm 放在 \(F_t(\cdot)\) 外面:\(x_{t+1} = x_t + Norm(F_t(x_t))\)。这样不合理——对网络输出做 Norm 会改变 logit 值的分布,影响收敛。把 Norm 放到里面,对模型输入做归一化更合理。
class Qwen3DecoderLayer(nn.Module):
def __init__(self, config):
self.input_layernorm = RMSNorm(hidden_size)
self.self_attn = Qwen3Attention(...)
self.post_attention_layernorm = RMSNorm(hidden_size)
self.mlp = Qwen3MLP(...)
def forward(self, positions, hidden_states, residual):
# layernorm
if residual is None:
hidden_states, residual = self.input_layernorm(hidden_states), hidden_states
else:
hidden_states, residual = self.input_layernorm(hidden_states, residual)
# self attention
hidden_states = self.self_attn(positions, hidden_states)
# layernorm
hidden_states, residual = self.post_attention_layernorm(hidden_states, residual)
# SwiGLU MLP
hidden_states = self.mlp(hidden_states)
return hidden_states, residual
外置残差的核心价值在于:RMSNorm 天然需要 hidden + residual 来算归一化。如果残差埋在 hidden 里(标准写法),norm 只做归一化,加法要单独一个 kernel。拆开后 norm 一次完成"加法 + 归一化",省一次 kernel launch 和一次显存读写。
Qwen3Model¶
Transformer 主干:词嵌入 + 28 层 Decoder + 最终归一化,约 20 行代码。
class Qwen3Model(nn.Module):
def __init__(self, config):
# 词嵌入:token_id → [hidden_size],TP 下词表按行切分到各卡
self.embed_tokens = VocabParallelEmbedding(config.vocab_size, config.hidden_size)
# 28 个完全相同的 Qwen3DecoderLayer
self.layers = nn.ModuleList([Qwen3DecoderLayer(config) for _ in range(config.num_hidden_layers)])
# 最终 RMSNorm,融合最后一层残差
self.norm = RMSNorm(config.hidden_size, eps=config.rms_norm_eps)
def forward(self, input_ids, positions):
hidden_states = self.embed_tokens(input_ids) # token → 向量
residual = None
for layer in self.layers: # 逐层过:attn → MLP
hidden_states, residual = layer(positions, hidden_states, residual)
hidden_states, _ = self.norm(hidden_states, residual) # 最后一次 norm,丢弃残差
return hidden_states
没有位置嵌入——因为 Qwen3Attention 里的 RoPE 已经在每层 attention 中注入了位置信息,embed_tokens 只做词嵌入。_ = self.norm(...) 显式丢弃残差,表示输出只有 hidden_states 一条路,不需要再往下传残差了。
Qwen3ForCausalLM¶
最外层:Qwen3Model + lm_head。forward 只输出 hidden_states,compute_logits 单独映射到词表。
class Qwen3ForCausalLM(nn.Module):
# HF checkpoint → 代码融合模块的映射表
packed_modules_mapping = {
"q_proj": ("qkv_proj", "q"),
"k_proj": ("qkv_proj", "k"),
"v_proj": ("qkv_proj", "v"),
"gate_proj": ("gate_up_proj", 0),
"up_proj": ("gate_up_proj", 1),
}
def __init__(self, config):
self.model = Qwen3Model(config) # Transformer 主干
self.lm_head = ParallelLMHead(vocab_size, hidden_size) # hidden → vocab
if config.tie_word_embeddings:
# 输入 embedding 和输出 lm_head 共享权重,省 ~1GB 参数
self.lm_head.weight.data = self.model.embed_tokens.weight.data
def forward(self, input_ids, positions):
return self.model(input_ids, positions) # → [N, hidden_size]
def compute_logits(self, hidden_states):
return self.lm_head(hidden_states) # → [N, vocab_size]
forward 和 compute_logits 分开的原因是 CUDA graph——录制时只到 hidden_states 截止,replay 后再单独取 logits,避免把 [vocab_size] 的矩阵塞进 graph 省显存。
tie_word_embeddings 让输入层和输出层共享同一份权重。同一个词进来时的 embedding 向量和出去时的 logits 投影来自同一块参数——省参数,也加速收敛。
Last update: May 13, 2026
Discussion