Transformer¶
约 2979 个字 预计阅读时间 10 分钟
视频链接:https://www.youtube.com/watch?v=ugWDIIOHtPA
Transformer 是一种 Sequence-to-Sequence(Seq2Seq)模型,与 RNN 和 CNN 一样,接收一个序列作为输入,输出另一个序列。但它有一个特别之处:在模型内部大量使用了 Self-Attention 这种特殊的层(Layer)。
在 Self-Attention 出现之前,序列建模主要依赖两种架构。
RNN(循环神经网络):
- 输入是一个序列(如 \(A_1, A_2, A_3, A_4\)),输出也是同一个长度的序列
- 每个位置的输出能考虑整个句子,因为有双向RNN(Bi-Directional RNN)
- 缺点:输出之间不能并行计算:必须先算完第1个才能算第2个
CNN(卷积神经网络):
- 用多个 Filter 扫过序列,每个 Filter 关注相邻的几个向量
- 优点:Filter之间可以并行计算
- 缺点:单层 CNN 只考虑局部信息(如只考虑3个向量),要看到长距离依赖需要叠很多层
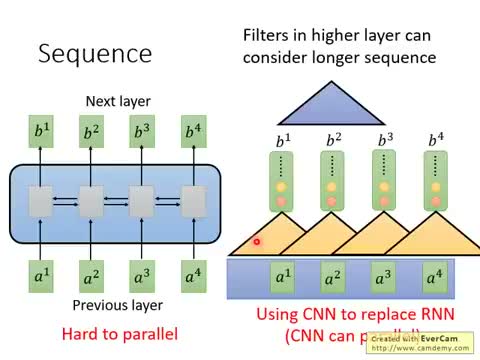
RNN 和 CNN 的根本矛盾
RNN 能看全局但串行慢,CNN 能并行但只能看局部。我们需要一种既能并行计算、又能让每个输出看到整个输入序列的层——这就是 Self-Attention。
Self-Attention¶
Q、K、V 的生成¶
Self-Attention 的第一步,是把序列中的每一个输入向量 \(A_i\) 转换成三个不同的向量:
- Query (\(Q\)):负责"去匹配"其他位置的键——相当于搜索引擎中的"查询词"
- Key (\(K\)):负责"被匹配"——相当于数据库中的"索引键"
- Value (\(V\)):包含要被抽取的实际信息——相当于"被检索到的内容"
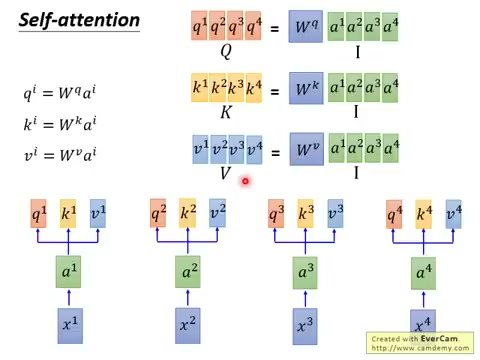
这三个向量是通过三个不同的可学习矩阵 \(W^Q, W^K, W^V\) 对输入做线性变换得到的:
其中: - \(A_i\) 是第 \(i\) 个位置的输入向量 - \(W^Q, W^K, W^V\) 是三个可学习的权重矩阵 - \(Q_i, K_i, V_i\) 分别是第 \(i\) 个位置的 Query、Key、Value
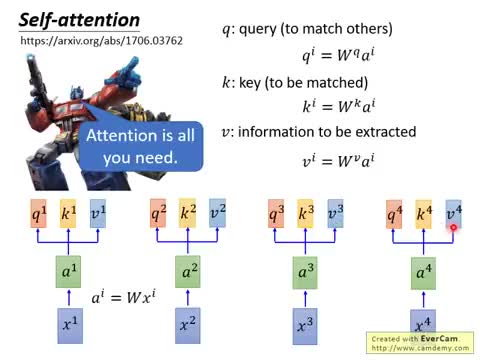
Scaled Dot-Product Attention¶
有了每个位置的 Q、K、V 后,计算 Self-Attention 的核心步骤如下:
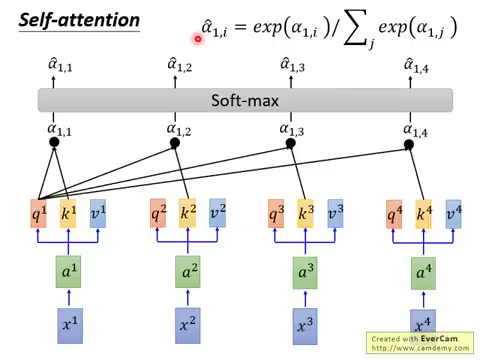
步骤一:计算 Attention 权重。对每个 Query \(Q_i\),拿它去和所有 Key \(K_j\)(包括自己)做 Dot-Product,得到注意力分数 \(\alpha_{ij}\):
其中 \(d\) 是 Q 和 K 的维度。除以 \(\sqrt{d}\) 是为了防止当 \(d\) 很大时,点积的数值过大导致后续 Softmax 梯度消失——这也是为什么这个方法叫做 Scaled Dot-Product Attention。
为什么除以 \(\sqrt{d}\)?
当 Query 和 Key 的向量维度 \(d\) 很大时(如512),它们的点积会变大。点积大意味着 Softmax 后的概率分布会变得非常尖锐(几乎所有概率集中在一个位置),梯度接近零,学习不起作用。除以 \(\sqrt{d}\) 是为了把数值拉回合理的范围。
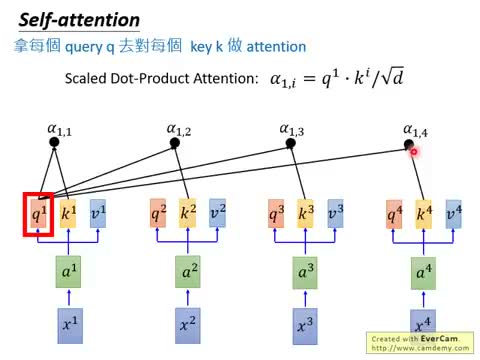
步骤二:Softmax 归一化。对所有 \(\alpha_{i1}, \alpha_{i2}, \ldots, \alpha_{in}\) 应用 Softmax 函数,得到归一化后的注意力权重 \(\hat{\alpha}_{ij}\):
经过 Softmax 后,\(\sum_j \hat{\alpha}_{ij} = 1\),即每个位置对所有位置的关注度总和为 1。
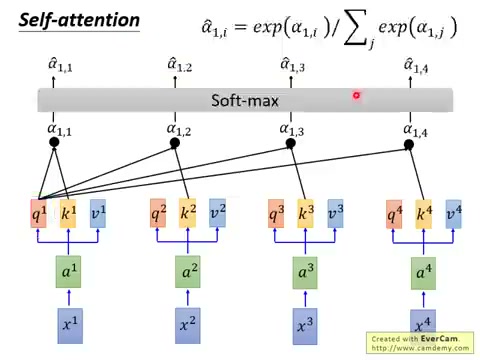
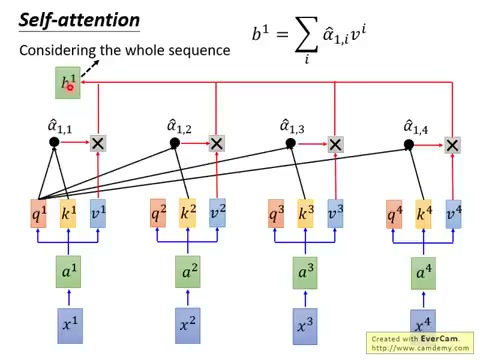
步骤三:加权求和。用归一化的注意力权重 \(\hat{\alpha}_{ij}\) 对所有 Value \(V_j\) 做加权求和,得到第 \(i\) 个位置的输出 \(B_i\):
这意味着 \(B_i\) 融合了整个序列的信息——每个位置的信息按其对位置 \(i\) 的相关性被加权聚合。
矩阵形式的 Self-Attention¶
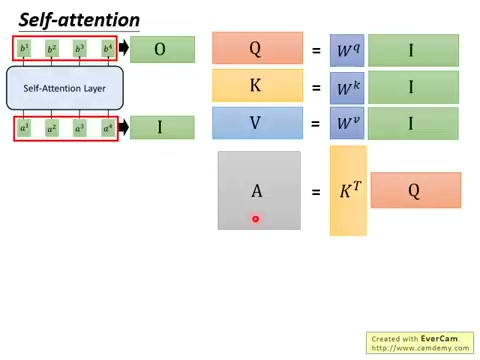
以上过程可以用矩阵运算一次性完成。设输入序列矩阵为 \(A\),则:
- \(Q = A \cdot W^Q\),\(K = A \cdot W^K\),\(V = A \cdot W^V\)
- \(\text{Attention}(Q, K, V) = \text{Softmax}\left(\frac{QK^T}{\sqrt{d}}\right) \cdot V\)
重要:Self-Attention 的完整矩阵公式
\[\text{Attention}(Q, K, V) = \text{Softmax}\left(\frac{QK^T}{\sqrt{d}}\right) V\]其中: - \(Q, K, V\) 分别是 Query、Key、Value 矩阵(每行对应序列中的一个位置) - \(QK^T\) 计算了所有 Query 和所有 Key 之间的点积(得到一个方阵) - \(\sqrt{d}\) 是缩放因子,\(d\) 是 Q 和 K 的向量维度 - Softmax 沿 Key 维度进行,使每行和为 1 - 最终结果乘以 \(V\) 得到加权的 Value 聚合
Multi-Head Attention¶
单一的 Self-Attention 只能关注一种"相关性模式"。Multi-Head Attention 通过多个独立的注意力头,让模型同时关注不同类型的关联:
- 每个头有自己的 \(W^Q, W^K, W^V\) 矩阵
- 每个头独立计算 Self-Attention,得到各自的输出
- 将所有头的输出拼接(Concatenate)起来,再通过一个线性变换 \(W^O\) 得到最终输出
Multi-Head Attention 的设计动机
不同头可以学会关注不同的关系类型:有的头可能关注局部语法关系(如形容词修饰哪个名词),有的头可能关注长距离语义关系(如代词指代哪个实体),有的头可能关注位置关系。多个头让模型在同一个位置上具备多种"视角"。
头部数(\(h\))是一个超参数,Transformer 原论文中 \(h=8\),实际使用中常见 \(h=8, 12, 16\) 等。
Positional Encoding¶
Self-Attention 的一个根本局限是没有内置的位置信息——对于 Self-Attention 来说,"我爱你"和"你爱我"在向量运算上没有区别,因为每个位置都与其他所有位置做无差别的全局交互。
解决办法是位置编码(Positional Encoding):在输入向量 \(A_i\) 上叠加一个代表位置索引 \(i\) 的向量 \(e_i\),使得:
其中 \(e_i\) 有很多种生成方式:
- Sinusoidal Encoding(原论文方案):使用不同频率的正弦/余弦函数生成,不同维度对应不同频率
- Learned Positional Encoding:将位置编码设为可学习参数,端到端训练
- 相对位置编码:编码的不是绝对位置,而是两个位置之间的相对距离
Transformer 的完整架构¶
原始 Transformer 是一个 Encoder-Decoder 的 Seq2Seq 架构,典型任务是机器翻译。输入端读入源语言句子,Encoder 把它编码成一串上下文化表示;输出端 Decoder 根据 Encoder 的结果和已经生成的目标词,逐步预测下一个词。
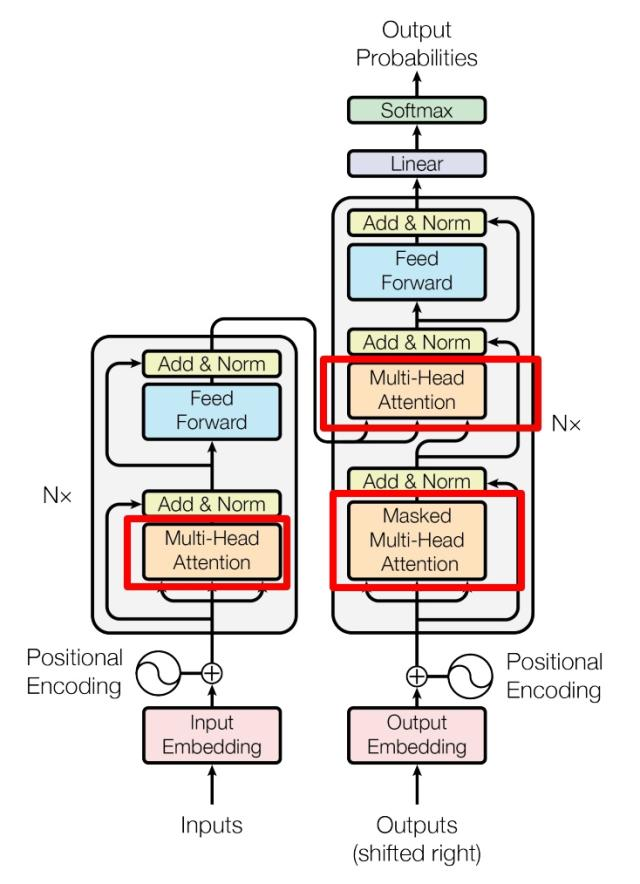
完整的数据流可以按下面的顺序理解:
- 输入序列先变成向量:每个 token 经过 Embedding 得到词向量,再加上 Positional Encoding,让模型知道 token 在序列中的位置。
- Encoder 读取整个输入序列:输入向量依次通过 \(N\) 个相同的 Encoder Layer。原论文中 \(N=6\)。
- Encoder 输出一组上下文表示:输出仍然是一串向量,长度与输入序列相同,但每个位置都已经融合了全句信息。
- Decoder 逐步生成目标序列:Decoder 接收已经生成的目标端 token,同时通过 Cross-Attention 读取 Encoder 的输出。
- Linear + Softmax 得到词概率:Decoder 最后一层输出会经过线性层和 Softmax,变成词表上每个词的概率分布。
重要:不要把“完整 Transformer”和“现在常说的大模型结构”混为一谈
- 原论文里的 Transformer 是 Encoder-Decoder 架构;BERT 主要使用 Encoder 部分,适合理解、分类、匹配等任务;GPT 类模型主要使用 Decoder-only 架构,适合自回归生成。理解原始 Encoder-Decoder 结构,可以帮助我们看清后续这些变体到底省略、保留或强化了哪一部分。
Encoder:把输入序列编码成上下文表示¶
Encoder 的任务不是直接生成词,而是把输入序列变成一组更有上下文的向量表示。每个 Encoder Layer 由两个核心子层组成:
- Multi-Head Self-Attention:让输入序列中的每个位置都可以关注其他所有位置。
- Position-wise Feed-Forward Network(FFN):对每个位置的向量分别做同一个两层前馈变换,增加非线性表达能力。
每个子层外面都包着一层 Add & Norm:
这里的 \(x+\text{Sublayer}(x)\) 是残差连接,作用是保留原始输入并稳定梯度;LayerNorm 则对每个位置的特征维度做归一化,让深层堆叠更容易训练。
因此,一个 Encoder Layer 的计算可以概括为:
其中:
- \(X\) 是进入当前 Encoder Layer 的序列表示。
- \(H_1\) 是经过自注意力和 Add & Norm 后的结果。
- \(H_2\) 是经过 FFN 和 Add & Norm 后的结果,也是该层 Encoder 的输出。
Encoder 中的 Self-Attention 是双向的:每个位置可以看见输入序列里的所有位置,包括自己、前面的词和后面的词。这一点和 Decoder 的 Masked Self-Attention 不同。Encoder 的目标是理解整个输入,因此不需要遮住未来信息。
FFN 为什么叫 Position-wise?
FFN 不是把不同位置混在一起处理,而是对每个位置的向量单独套用同一组参数。位置之间的信息交换主要发生在 Self-Attention 子层;FFN 的作用是在每个位置内部做更强的特征变换。
Decoder:在已生成内容的基础上预测下一个词¶
Decoder 的结构比 Encoder 多一个注意力子层。每个 Decoder Layer 通常包含三个核心子层:
- Masked Multi-Head Self-Attention:只允许当前位置关注已经生成的目标端 token,不能看未来 token。
- Cross-Attention(Encoder-Decoder Attention):让 Decoder 读取 Encoder 的输出。
- Position-wise FFN:和 Encoder 中一样,对每个位置做前馈变换。
Decoder 的第一层注意力为什么要加 Mask?因为生成任务是自回归的:预测第 \(i\) 个词时,只能依赖第 \(1\) 到 \(i-1\) 个已经生成的词。如果训练时让模型看到标准答案里未来位置的词,它就会“偷看答案”,推理时性能会崩掉。因此 Masked Self-Attention 会把未来位置的注意力分数屏蔽掉。
Cross-Attention 是理解 Decoder 的关键。它不是普通的 Self-Attention,因为 Q、K、V 的来源不同:
- Query 来自 Decoder 当前层的表示:表示“我现在生成到这里,需要从输入句子里找什么信息?”
- Key 和 Value 来自 Encoder 的最终输出:表示“输入句子的每个位置有什么信息可以被读取?”
- 输出回到 Decoder 流程中:Decoder 借此把源语言信息和目标端已生成信息结合起来。
所以 Decoder Layer 的计算逻辑可以简化成:
- 先在目标端内部做 Masked Self-Attention,整理“已经生成的上下文”。
- 再用 Cross-Attention 去 Encoder 输出中查找与当前生成位置相关的源端信息。
- 最后用 FFN 对每个位置做非线性变换。
- 每个子层后都接 Add & Norm,保持训练稳定。
训练和推理时 Decoder 的用法不同
训练时,目标序列通常一次性输入 Decoder,但通过 Mask 保证每个位置只能看到它之前的词。推理时没有完整目标序列,模型必须从起始符开始,一个词一个词生成;每生成一个新词,再把它作为下一步 Decoder 的输入。
Add & Norm、FFN 和输出层的位置¶
Transformer 图中反复出现的 Add & Norm 可以理解为每个子层外面的“稳定器”:Add 是残差连接,Norm 是 Layer Normalization。无论是 Encoder 的 Self-Attention、Encoder 的 FFN,还是 Decoder 的 Masked Self-Attention、Cross-Attention、FFN,后面都会接 Add & Norm。
FFN 一般写作:
实际实现里也常把 ReLU 换成 GELU。它的输入输出维度通常保持一致,中间层维度更大,用来提升每个 token 表示的表达能力。
Decoder 最后一层输出后,还要接一个 Linear + Softmax。Linear 把隐藏向量映射到词表大小,Softmax 把它变成概率分布。概率最高的词,或者采样得到的词,就是当前步的生成结果。
Last update: May 12, 2026
Discussion