为什么 DeepSeek 这么便宜¶
约 4901 个字 预计阅读时间 16 分钟
逐层拆解 DeepSeek V4 背后的模型结构、缓存机制和推理系统取舍。
一、价格差距有多大¶
1.1 一组价格对比¶
| DeepSeek V4-Flash | OpenAI GPT-4o | |
|---|---|---|
| 输入(缓存命中) | ¥0.02 / MTok | $1.25 / MTok(约 ¥9) |
| 输入(正常) | ¥1 / MTok | $2.50 / MTok(约 ¥18) |
| 输出 | ¥2 / MTok | $10 / MTok(约 ¥72) |
只看缓存命中输入价,价差大约是 450 倍。即使不算缓存,正常输入价也差了接近 20 倍。
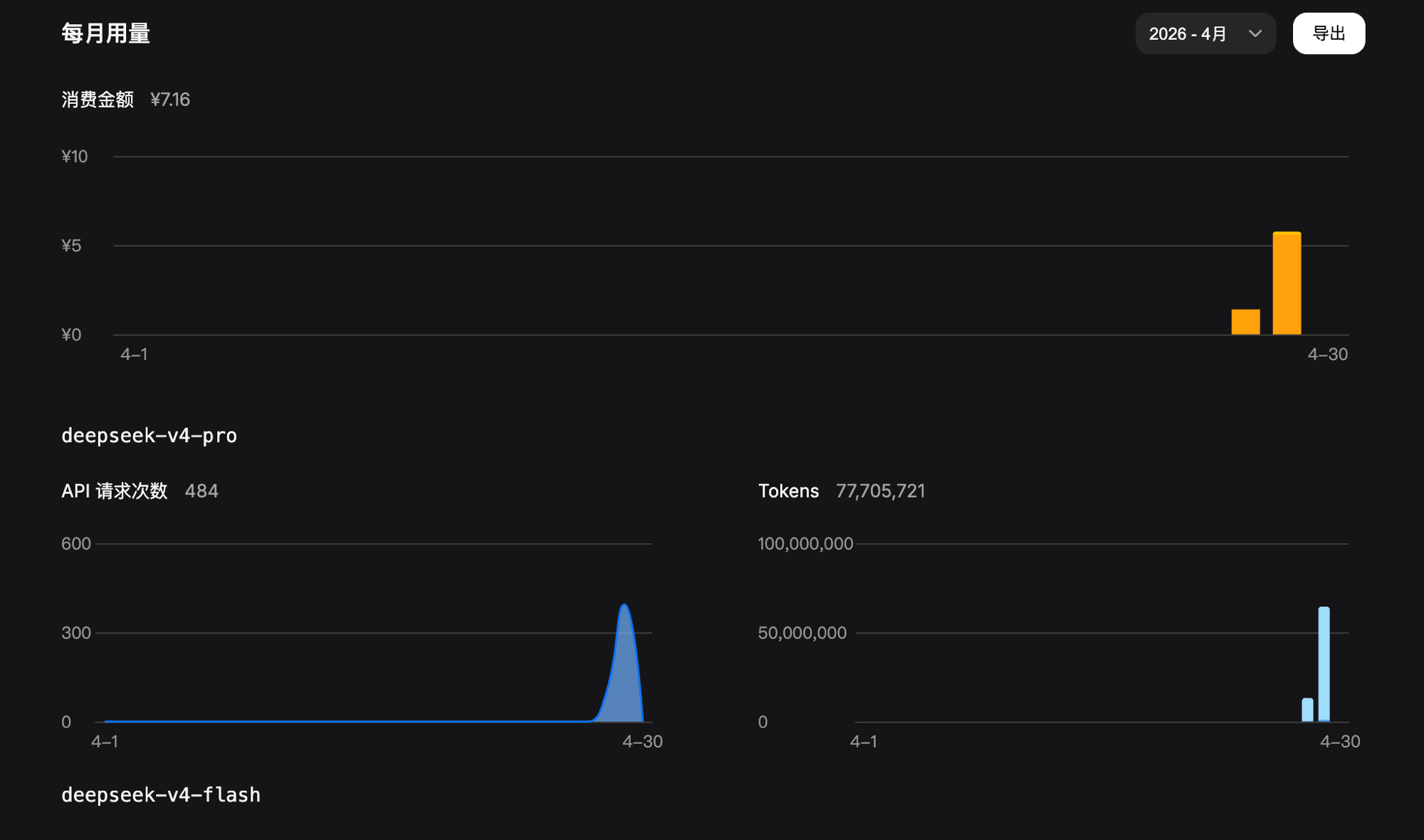
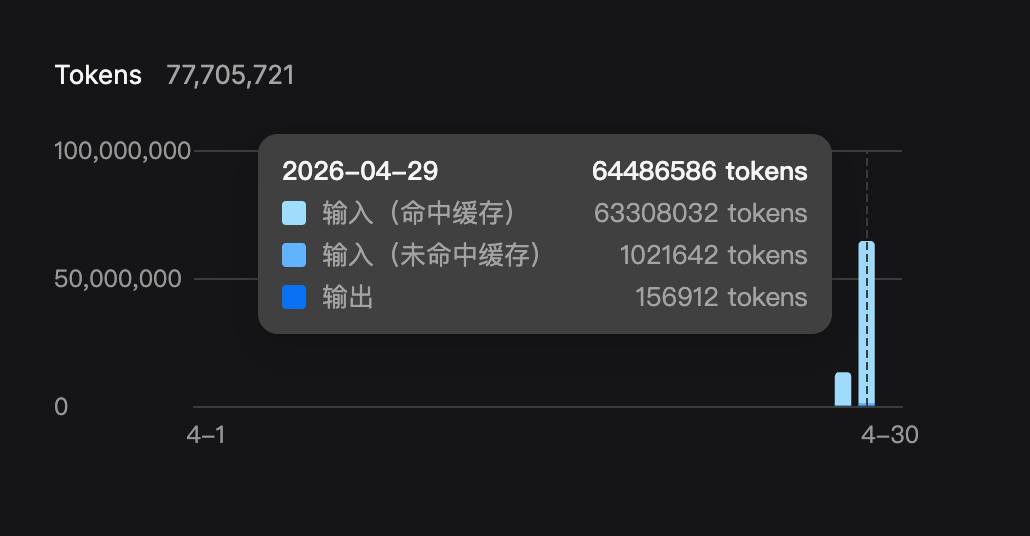
DeepSeek 官方还给过一个很关键的数据:用户平均超过 50% 的 token 命中缓存。长 system prompt、多轮对话、Few-shot、长文档问答这类场景,命中率还会更高。也就是说,很多用户真实付费成本不是按"正常输入价"算,而是大量落在"缓存命中价"上。
价格数据来自 DeepSeek 与 OpenAI 官方定价页(2026.04);GPT-4o 美元价格按约 7.2 汇率换算为人民币参考值。
1.2 先拆清两个问题¶
"DeepSeek 为什么便宜"其实包含两个不同问题:
第一,缓存命中为什么这么便宜?
这主要是 API Infra 的问题。相同前缀不再反复 prefill,而是从缓存里把已经算好的 KV 取回来。DeepSeek 的上下文硬盘缓存就是在做这件事。
第二,V4 长上下文本身为什么能便宜地跑?
这是模型结构的问题。V4 的关键变化不是继续只靠 MLA,而是引入 Hybrid Attention(CSA + HCA),把 1M context 下的 KV cache 和 attention 计算继续压低。
这两个问题最后会合在一起:
模型侧:Hybrid Attention + MoE + FP4/FP8
→ 单次长上下文推理更便宜
API 侧:Prefix Caching + 磁盘 KV Cache
→ 重复前缀不再重复 prefill
产品侧:激进定价
→ 成本优势转化为用户看到的低价
二、第一层:缓存命中为什么便宜¶
2.1 推理的两个阶段¶
Decoder-only 模型(如 GPT、DeepSeek)的每次请求,在服务端都可以拆成两个阶段:
| 阶段 | 做什么 | 主要瓶颈 |
|---|---|---|
| Prefill | 并行处理所有输入 token,生成 KV 向量 | compute-bound |
| Decode | 逐 token 自回归生成输出 | memory-bound |
Prefill 是长 prompt 的主要成本来源。如果你发了 128K token 的输入,模型必须先处理完整上下文,算出这些 token 的 KV,才能生成第一个输出 token。
Transformer attention 的核心操作是:
序列越长,prefill 里的 attention 计算越重。长 system prompt、长文档上下文、Few-shot 示例反复出现时,最浪费的地方就是:同一段前缀被一次又一次重新算。
DeepSeek 在 2024.08 的上下文硬盘缓存公告里给过实测数字:128K prompt 的首 token 延迟从约 13s 降到约 500ms(缓存命中)1。
2.2 以存换算:到底换掉了什么¶
缓存命中之所以便宜,不是因为模型"少看了一点输入",也不是因为输出质量变差了。它省掉的是 重复 prefill。
传统方式:
请求1: [system_prompt][doc_A] → prefill → decode → 释放 KV
请求2: [system_prompt][doc_B] → 重新 prefill system_prompt → decode
请求3: [system_prompt][doc_C] → 重新 prefill system_prompt → decode
缓存方式:
请求1: [system_prompt][doc_A] → prefill → KV 写入缓存
请求2: [system_prompt][doc_B] → 加载 system_prompt 的 KV → 只算 doc_B
请求3: [system_prompt][doc_C] → 加载 system_prompt 的 KV → 只算 doc_C
这里的账可以分四层看。
第一层:GPU 计算时间。
128K prompt 完整 prefill 需要大量矩阵计算。缓存命中后,公共前缀的这部分计算直接跳过。DeepSeek 给出的 13s 到 500ms,本质上就是用一次磁盘/内存加载,替代一次长 prompt prefill。
第二层:GPU 资源占用。
prefill 是 compute-bound,会占用 GPU 计算单元。命中缓存后,GPU 不再为公共前缀重复做大矩阵计算,这些算力可以让给别的请求。对服务商来说,这不是只省了一个用户的延迟,而是提高了整套集群的吞吐。
第三层:缓存成本摊销。
第一次请求仍然要算,也要把 KV 写入缓存。但只要同一前缀后面继续出现,缓存成本就会被摊薄:
命中次数越多,单次请求摊到的成本越低。system prompt、多轮 agent 轨迹、固定工具说明、长文档模板,都是这种模式。
第四层:用户计费。
DeepSeek 把这部分节省直接体现在价格表里:缓存命中的输入 token 按更低价格计费。于是用户看到的不是"服务商内部省了一点 GPU",而是输入 token 单价真的降到了 ¥0.02 / MTok。
所以"以存换算"更准确地说,是:
磁盘本身当然比 HBM 慢,但这里比较的不是"磁盘读一次"和"显存读一次",而是"加载已经算好的 KV"和"重新跑完整长上下文 prefill"。只要 KV 足够小、加载链路足够异步、命中率足够高,这笔账就划算。
2.3 为什么这不等于普通的 prompt cache¶
很多平台也有 Prompt Caching,但实现边界不同。常见做法是把短期缓存留在 GPU/CPU 内存里,几分钟不用就清掉。这样做简单,延迟也低,但容量贵,缓存生命周期短。
DeepSeek 的上下文硬盘缓存更激进:把上下文 KV 持久化到服务器磁盘,缓存可以跨请求复用,保留时间也更长。问题随之变成:KV 必须足够小,磁盘加载必须足够快,调度系统必须能找到对应缓存。
这就引出下一层:模型结构本身要先把长上下文的 KV 和 attention 成本压下来。
三、第二层:V4 Hybrid Attention 降低长上下文成本¶
3.1 KV 成本为什么会压垮长上下文¶
标准 MHA(Multi-Head Attention)里,每层都要为每个 token 保存 K 和 V:
序列长度越长,KV cache 线性增长;decode 时还要不断访问历史 KV。上下文从 128K 拉到 1M 后,问题不只是"窗口够不够大",而是:
- KV cache 要占多少显存 / 内存 / 磁盘;
- decode 每一步要读多少历史;
- attention 计算要不要扫完整长序列;
- 多用户并发时,缓存调度是否扛得住。
3.2 V2/V3:MLA 先压每个 token 的 KV¶
DeepSeek V2 提出的 MLA(Multi-head Latent Attention) 是早期成本优势的基础。它解决的是"每个 token 存多少 KV"的问题。
MHA 中,每个 head 都存 K 和 V:
MLA 引入低秩压缩:
它不是把上下文变短,而是把每个位置要存的 KV 表示变小。
这解释了 DeepSeek 早期为什么有长上下文和缓存上的成本优势。但到 V4,如果还只讲 MLA,就漏掉了最关键的新变化。
3.3 V4:Hybrid Attention 继续压序列维成本¶
DeepSeek V4 的官方模型卡把核心架构写成 Hybrid Attention Architecture:组合 Compressed Sparse Attention(CSA) 和 Heavily Compressed Attention(HCA),目标是提高 1M token 长上下文推理效率2。
这一步解决的是另一个问题:上下文变长后,不只是每个 token 的 KV 要小,序列维度上的 KV 数量和 attention 计算也要降下来。
粗略理解:
MLA:
压每个 token 的 KV 表示
重点是 "单个位置存得更省"
V4 Hybrid Attention:
CSA:沿序列维压缩 KV,再做稀疏选择
HCA:大幅压缩序列维 KV,在短序列上做 dense attention
重点是 "很长的历史不要完整扫一遍"
(压缩倍数参见 V4 模型卡 [^2])
vLLM 对 V4 的实现说明也把挑战拆成两类:KV cache memory growth 和 attention computation cost。V4 的新 attention 机制同时处理这两件事:共享 K/V、压缩跨 token 的 KV cache,并结合 sparse attention 限制长上下文 attention 计算3。
官方模型卡给出的结果是:在 1M-token context 下,DeepSeek-V4-Pro 的 single-token inference FLOPs 约为 DeepSeek-V3.2 的 27%,KV cache 约为 10%2。Hugging Face 的 V4 解读还补充:V4-Flash 在同样 1M context 下约为 10% FLOPs / 7% KV cache4。
这就是 V4 便宜的模型侧主因。不是"缓存命中价"本身由 Hybrid Attention 直接决定,而是 Hybrid Attention 先让长上下文推理的底层成本降下来;再叠加 API 侧的 Prefix Caching,缓存命中价才有空间打到很低。
四、补充:V4 其他 feature 与低价的关系¶
DeepSeek V4 的新 feature 很多,但和"为什么便宜"的关系不一样。有些直接影响推理成本,有些主要影响训练稳定性或 agent 能力。
| V4 feature | 作用 | 和低价 / 缓存的关系 |
|---|---|---|
| Hybrid Attention(CSA + HCA) | 沿序列维压缩 KV,并降低长上下文 attention 计算 | 强相关。 这是 V4 模型侧降本的主线,直接解释 1M context 下 KV cache 和 FLOPs 为什么能降到 V3.2 的一小部分 |
| DeepSeekMoE:Pro 49B active / Flash 13B active 2 | 总参数很大,但每次只激活一部分专家 | 强相关。 MoE 降低每 token 前向计算量,Flash 的 13B active 直接服务低价定位 |
| FP4 + FP8 Mixed Precision | Instruct 模型里 MoE expert 参数用 FP4,多数其他参数用 FP82 | 中强相关。 它降低权重存储、显存带宽和部署压力,但不是 prefix cache 命中的核心机制 |
| 1M-token context | V4 的长上下文能力目标 | 结果相关。 1M context 本身不是降本原因,它反过来要求 attention 和 KV 必须更便宜 |
| mHC(Manifold-Constrained Hyper-Connections) | 强化残差连接,改善超大模型训练和信号传播稳定性2 | 间接相关。 它让千亿级 active 这种大模型更稳定,但不直接解释缓存命中为什么便宜 |
| Muon Optimizer | 提升训练收敛速度和稳定性2 | 间接相关。 它影响训练成本和模型质量,不是推理缓存低价的直接原因 |
| 两阶段 post-training / on-policy distillation | 先培养领域专家,再统一蒸馏整合2 | 弱到中等相关。 它解释能力和性价比,不解释 KV cache 为什么省 |
| 三种 reasoning mode:Non-think / Think High / Think Max | 给不同任务不同推理预算 | 中等相关。 它是产品侧的成本控制:简单任务用低预算,复杂任务再开高预算 |
| Interleaved thinking、DSML 工具调用格式、DSec RL 沙箱 | 面向 agent 工作流,提升长任务、工具调用和 RL 训练能力4 | 和"好用"相关,但和"缓存便宜"间接相关。 Agent 轨迹很长,越依赖长上下文,越能体现 Hybrid Attention 的价值 |
可以把它们归成三类:
模型侧降本:
Hybrid Attention + MoE + FP4/FP8
API 侧复用:
磁盘 KV Cache / Prefix Caching
产品侧调度:
1M context + reasoning modes + 面向 agent 的 post-training / infra
其中,Hybrid Attention 是 V4 长上下文便宜的第一主因;Prefix Caching 和磁盘 KV Cache 是缓存命中输入价极低的直接原因;MoE 和低精度则继续压低每 token 的基础服务成本。
五、Prefix Caching 机制深度剖析¶
5.1 官方公开的机制¶
DeepSeek 在 2024.08 的上下文硬盘缓存公告和新版 Context Caching guide 里公开了以下机制15:
- 缓存单位:以 64 token 为最小存储单元,小于 64 token 的内容不会被缓存。
- 命中对象:新版 guide 称为 cache prefix unit。每个 cached prefix 是独立、完整的单元,后续请求必须完整匹配这个单元才会命中。
- 匹配规则:必须从第 0 个 token 开始,前缀完整复用才会命中。中间部分的局部匹配不会触发命中。
- 存储方式:缓存在分布式磁盘阵列上(不是 GPU 显存或 CPU 内存)。
- 生命周期:未使用的缓存会在几小时到几天内自动清除。
- 效果:128K prompt 的首 token 延迟从约 13s 降到约 500ms(缓存命中时)。
- 可观测性:API 响应中返回
prompt_cache_hit_tokens和prompt_cache_miss_tokens,用户可以知道自己命中了多少 token。
这里要避免一个误解:64 token 是底层存储粒度,cache prefix unit 是命中规则里的完整前缀单元。 更准确的说法不是"一个 cache prefix unit 一定等于 64 token",而是 DeepSeek 的缓存以 64 token 为存储粒度,命中时要求完整匹配已经持久化的 cache prefix unit。
对比业界其他 Prompt Caching 方案(如 OpenAI 的 5-10 分钟显存缓存),DeepSeek 的选择更激进:用磁盘换容量,用持久化换命中率。
5.2 Cache prefix unit 如何被持久化¶
新版 guide 明确列了三种持久化时机5:
| 时机 | 触发条件 | 目的 |
|---|---|---|
| 请求边界持久化 | 每次请求的输入结束点和输出结束点 | 保底覆盖,后续请求能完整复用上一轮输入 / 输出前缀 |
| 公共前缀检测持久化 | 多个请求出现公共前缀 | 把公共部分提取成独立 cache prefix unit |
| 固定 token 间隔持久化 | 长输入 / 长输出超过阈值 | 避免超长前缀因为迟迟不到边界而完全不可缓存 |
这个机制解释了为什么有些场景不是第二次请求就命中,而是第三次才命中。比如长文档问答:
请求1: [system_prompt + report][问题A]
→ 持久化的是整个请求边界上的 prefix unit
请求2: [system_prompt + report][问题B]
→ 不能完整匹配请求1的 prefix unit
→ 系统检测到公共前缀 [system_prompt + report]
→ 将公共前缀持久化为独立 cache prefix unit
请求3: [system_prompt + report][问题C]
→ 完整匹配公共前缀 unit
→ 命中缓存
这不是系统故障,而是缓存构建的渐进过程。DeepSeek 官方也把缓存描述为 best-effort,不保证 100% 命中。
5.3 基于公开信息的链路重构¶
以下是对 DeepSeek 缓存系统工作方式的工程重构,基于公告中的公开信息,但不代表官方实现细节:
缓存单元的粒度含义
64 token 的最小单元意味着:更短的 prompt 不会落盘;长 prompt 在切分和持久化时,会受到 64-token 粒度约束。它和 vLLM 的固定 block 粒度有相似之处,但 DeepSeek API 的重点不只是 block 切分,而是把可复用前缀持久化到磁盘,并对 API 用户透明计费。
异步处理
从公开的效果看(用户感知不到缓存引入的额外延迟),KV 的加载和写入大概率是异步化的:加载可以和请求排队、调度重叠;写入可以在请求完成后进行,不阻塞 decode。这种异步流水线是高性能推理系统的常见设计模式。
完整流程
请求到达 →
对前缀按 64-token 边界切分、Hash →
├─ 命中索引 → 从磁盘加载 KV → 跳过对应 prefill
└─ 未命中 → 正常 prefill → KV 异步写回磁盘缓存
→ Decode → 流式返回
六、和 vLLM / SGLang 的对比¶
这里要先说清楚:这个对比不是说 vLLM 或 SGLang "不支持 V4 attention"。vLLM 已经在支持 DeepSeek V4 的长上下文 attention 实现。这里对比的是 缓存系统默认策略、存储层级、跨请求持久化能力。
6.1 开源社区的主流缓存方案¶
vLLM — Block-level Hash Caching
vLLM 把 KV Cache 按固定大小的 block(通常 16 token)切分,每个 block 基于 token 序列计算 hash。请求到达时,对前缀的每个 block 计算 hash,再查表复用。
优点是简单、查找快、工程上可靠。限制是缓存主要还是围绕 GPU / CPU 内存管理,容量和持久化时间天然受限。
SGLang — Radix Tree Caching
SGLang 用 Radix Tree 组织 KV Cache,新请求在前缀树上做最长匹配。
请求1: [system_prompt_v1][user_query_A] → 完整 prefill → KV 存入 Radix Tree
请求2: [system_prompt_v1][user_query_B] → 前缀匹配到 system_prompt_v1
→ 复用其 KV → 只 prefill user_query_B
请求3: [system_prompt_v2][user_query_C] → 和 v1 前缀不同 → 无法复用
SGLang 的 Radix Tree 按 token 序列做最长前缀匹配,比固定 block hash 更灵活——任意长度的公共前缀都能命中,不要求对齐到 16 或 64 token 的边界。代价是树结构维护成本更高,缓存容量也仍然受内存层级约束。
6.2 DeepSeek 的差异化¶
| vLLM | SGLang | DeepSeek API | |
|---|---|---|---|
| 匹配方式 | Block Hash | Radix Tree | 单元 Hash + 公共前缀检测 |
| 典型粒度 | 固定 block | 任意长度前缀 | 64 token 单元 |
| 缓存位置 | GPU / CPU 内存为主 | GPU / CPU 内存为主 | 服务器磁盘 + 多级缓存 |
| 缓存时长 | 更偏请求级 / 进程级 | 更偏请求级 / 进程级 | 小时到天级 |
| 跨请求复用 | 有,但依赖部署和生命周期 | 有,但依赖部署和生命周期 | 对 API 用户透明 |
| 用户感知 | 自己部署、自己调参 | 自己部署、自己调参 | 默认享受缓存命中价 |
核心差异是 存储层级下沉和产品化程度。开源推理引擎更像是给你工具,让你自己管理缓存生命周期;DeepSeek API 是把这套缓存系统产品化,命中时直接反映到价格和延迟上。
6.3 可能存在的额外优化(推测)¶
以下是基于公开行为和推理系统常见设计的合理推测,不当成官方事实:
1. 多级冷热分层
热点前缀可能留在内存或显存,冷缓存落盘。高频命中走更快路径,低频缓存也不挤占昂贵资源。
2. 跨节点缓存寻址
大规模部署中,同一用户请求不一定总在同一台机器上。系统需要知道某个 prefix unit 存在哪个节点,或者把热点单元复制到多个节点。
3. 异步预加载
请求刚到达时就根据 hash 发起缓存加载,让磁盘 IO 和排队 / 调度重叠。这样命中缓存不一定会显著增加用户感知延迟。
4. 单元合并与分裂
高频连续单元可能合并,低频长单元可能拆分。目标都是提高命中效率和空间利用率。
七、总结:三层驱动的飞轮¶
DeepSeek 的低价不是单点优化。
Layer 1: 模型架构
Hybrid Attention + MoE + FP4/FP8
→ 长上下文单次推理更便宜
Layer 2: API Infra
Prefix Caching + 磁盘 KV Cache
→ 重复前缀不再重复 prefill
Layer 3: 定价策略
把成本优势体现在价格表
→ 缓存命中 ¥0.02 / MTok
如果只看缓存,会漏掉 V4 Hybrid Attention 对 1M 长上下文成本的压缩;如果只看模型结构,又解释不了为什么"缓存命中输入价"能单独便宜到 ¥0.02 / MTok。
完整答案是:模型侧先把长上下文推理成本打下来,Infra 侧再把重复前缀复用起来,最后 DeepSeek 把这部分成本优势直接让到 API 定价里。
这也是它难被简单复制的地方。做一个 API 层缓存不难,难的是底层 attention、MoE、低精度、缓存持久化、跨节点调度、定价体系一起成立。
-
DeepSeek API Docs — 上下文硬盘缓存(2024.08.02):128K prompt 首 token 从 13s 降至 500ms(缓存命中)。 ↩↩
-
DeepSeek-AI Hugging Face Model Card — DeepSeek-V4-Pro: Towards Highly Efficient Million-Token Context Intelligence. Model card states V4 combines CSA and HCA, and V4-Pro uses 27% single-token inference FLOPs and 10% KV cache compared with V3.2 at 1M context. ↩↩↩↩↩↩↩
-
vLLM Blog — DeepSeek V4 in vLLM: Efficient Long-context Attention. It explains V4's KV sharing, cross-token KV compression, and sparse attention implementation. ↩
-
Hugging Face Blog — DeepSeek-V4: a million-token context that agents can actually use. It summarizes V4-Pro at 27% FLOPs / 10% KV and V4-Flash at 10% FLOPs / 7% KV in 1M context, and discusses V4's agent-oriented changes. ↩↩
-
DeepSeek API Docs — Context Caching. The guide describes cache prefix units, full-unit matching, persistence at request boundaries, common-prefix detection persistence, and persistence at fixed token intervals. ↩↩
Last update: April 30, 2026
Discussion